Generating Dataset for Channel Estimation Training
The first step in any deep learning project is preparing the dataset. In this notebook we create an OFDM communication pipeline and capture the received grid together with the DMRS information. Based on the known pilot signals (DMRS) and received values at those pilot locations, the Channel Estimation algorithms calculate the OFDM Channel Matrix for every pair of receive antenna and layer. Please note that since we are using DMRS pilots, the effect of precoding is included in the estimated channel.
Our Deep learning model is trained to predict one L x K OFDM channel matrix where L is the number of OFDM symbols per slot and K is the number of subcarriers. However, the channel matrix is a 4-D tensor of shape L x K x Nr x Nl, where Nr and Nl are the number of receiver antenna and the number of layers correspondingly. Therefore each channel matrix corresponds to Nc=Nr.Nl dataset samples. The following diagram shows how the data generation pipeline works.
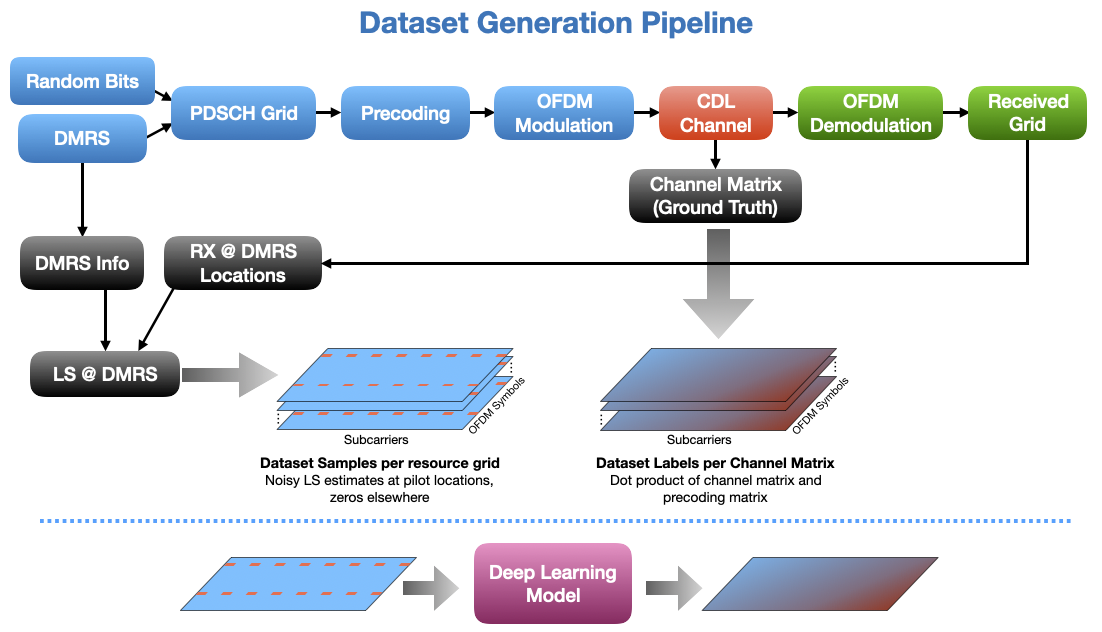
So, let’s get started by importing some modules from NeoRadium.
[1]:
import numpy as np
import scipy.io
import time
from neoradium import Carrier, PDSCH, CdlChannel, AntennaPanel, Grid, random
The getSamples function below receives the DMRS information, the received resource grid, and the ground-truth channel and creates pairs of dataset samples and labels. Each call to this function results in Nc=Nr.Nl dataset samples where Nr is the number of receiver antenna and Nl is the number of layers. This function first calculates the channel values at the pilot locations using least squares (LS) method. Each dataset sample is an L x K complex matrix which is initialized
with zeros and updated by the channel values at pilot locations. The ground-truth channel is also broken down to Nc matrixes which are used as labels for the corresponding dataset samples.
[2]:
def getSamples(dmrs, rxGrid, actualChannel):
rsGrid = rxGrid.bwp.createGrid( len(dmrs.pdsch.portSet) ) # Create an empty resource grid
dmrs.populateGrid(rsGrid) # Populate the grid with DMRS values
rsIndexes = rsGrid.getReIndexes("DMRS") # This contains the locations of DMRS values
rr, ll, kk = rxGrid.shape # Number of RX antenna, Number of symbols, Number of subcarriers
pp, ll2, kk2 = rsGrid.shape # Number of Ports (From DMRS)
assert (ll==ll2) and (kk==kk2)
samples = []
labels = []
for p in range(pp): # For each DMRS port (i.e. each layer)
portLs = rsIndexes[1][(rsIndexes[0]==p)] # Indexes of symbols containing pilots in this port
portKs = rsIndexes[2][(rsIndexes[0]==p)] # Indexes of subcarriers containing pilots in this port
ls = np.unique(portLs) # Unique Indexes of symbols containing pilots in this port
ks = portKs[portLs==ls[0]] # Unique Indexes of subcarriers containing pilots in this port
numLs, numKs = len(ls), len(ks) # Number of OFDM symbols and number of subcarriers
pilotValues = rsGrid[p,ls,:][:,ks] # Pilot values in this port
rxValues = rxGrid.grid[:,ls,:][:,:,ks] # Received values for pilot signals
hEst = np.transpose(rxValues/pilotValues[None,:,:], (1,2,0)) # Channel estimates at pilot locations
for r in range(rr): # For each receiver antenna
inH = np.zeros(rxGrid.shape[1:], dtype=np.complex128) # Create one 2D matrix with all zeros
for li,l in enumerate(ls):
inH[l,ks] = hEst[li,:,r] # Set the LS estimates at pilot location
samples += [ inH ] # The dataset sample for r'th antenna and p'th port (layer)
labels += [actualChannel[:,:,r,p]] # The channel matrix (Label) for r'th antenna and p'th port (layer)
return samples, labels
The makeDataset function below receives the number of time-domain frames (numFrames), the SNR values in dB (snrDbs), the seed values to initialize NeoRadium’s random generator (seeds), and a file name to save the dataset (fileName).
It implements the communication pipeline shown in the above diagram. For each OFDM slot, it uses the getSamples function above to create samples and labels. These samples and labels are then aggregated and saved to the file specified by the fileName.
[3]:
def makeDataset(numFrames, snrDbs, seeds, fileName=None):
freqDomain = False # Set to True to apply channel in frequency domain
carrier = Carrier(numRbs=51, spacing=30) # Create a carrier with 51 RBs and 30KHz subcarrier spacing
bwp = carrier.curBwp # The only bandwidth part in the carrier
# Create a PDSCH object
pdsch = PDSCH(bwp, interleavingBundleSize=0, numLayers=2, nID=carrier.cellId, modulation="16QAM")
pdsch.setDMRS(prgSize=0, configType=2, additionalPos=2) # Specify the DMRS configuration
numSlots = bwp.slotsPerFrame*numFrames # Total number of slots
samples, labels = [], []
totalIter = len(seeds) * numSlots * len(snrDbs) # Total number of iterations
curIter = 1 # Counter used for printed messages
t0 = time.time() # Start time for time estimation
print("Making dataset for SNR=%s dB, with %d frames and %d seeds"%(str(snrDbs), numFrames, len(seeds)))
for s,seed in enumerate(seeds): # For each seed the channel is initialized differently
random.setSeed(seed)
carrier.slotNo = 0 # Initialize the slot number
# Creating a CdlChannel object:
channel = CdlChannel('C', delaySpread=300, carrierFreq=4e9, dopplerShift=5,
txAntenna = AntennaPanel([2,2], polarization="x"), # 8 TX antenna
rxAntenna = AntennaPanel([1,1], polarization="+"), # 2 RX antenna
seed = seed,
timing = "nearest")
for snrDb in snrDbs: # For each SNR value in snrDbs
for slotNo in range(numSlots): # For each slot in the specified number of frames
grid = pdsch.getGrid() # Create a resource grid populated with DMRS
numBits = pdsch.getBitSizes(grid)[0] # Number of bits available in the resource grid
txBits = random.bits(numBits) # Create random binary data
pdsch.populateGrid(grid, txBits) # Map/modulate the data to the resource grid
channelMatrix = channel.getChannelMatrix(bwp) # Get the (ground-truth) channel matrix
precoder = pdsch.getPrecodingMatrix(channelMatrix) # Get the precoder matrix from the PDSCH object
precodedGrid = grid.precode(precoder) # Perform the precoding
if freqDomain:
rxGrid = precodedGrid.applyChannel(channelMatrix) # Apply the channel in frequency domain
rxGrid = rxGrid.addNoise(snrDb=snrDb) # Add noise
else:
txWaveform = precodedGrid.ofdmModulate() # OFDM Modulation
maxDelay = channel.getMaxDelay() # Get the max. channel delay
txWaveform = txWaveform.pad(maxDelay) # Pad with zeros
rxWaveform = channel.applyToSignal(txWaveform) # Apply channel in time domain
noisyRxWaveform = rxWaveform.addNoise(snrDb=snrDb, nFFT=bwp.nFFT) # Add noise
offset = channel.getTimingOffset() # Get timing info for synchronization
syncedWaveform = noisyRxWaveform.sync(offset) # Synchronization
rxGrid = syncedWaveform.ofdmDemodulate(bwp) # OFDM demodulation
# Get the dataset samples and labels for current slot
newSamples, newLabels = getSamples(pdsch.dmrs, rxGrid, channelMatrix @ precoder[None,...])
samples += newSamples
labels += newLabels
carrier.goNext() # Prepare the carrier object for the next slot
channel.goNext() # Prepare the channel model for the next slot
dt = time.time()-t0 # Get the duration of time since the beginning
percentDone = curIter*100/totalIter # Calculate the percentage of task done
if curIter == totalIter: continue # Last iteration
# Print messages about the progress
print("\r %%%d done in %d Sec. Estimated remaining time: %d Sec. "%
(int(percentDone), np.round(dt), np.round(100*dt/percentDone-dt)), end='')
curIter += 1
# Convert the samples and labels to numpy arrays with float values. Shape: N x L x K x 2
# N: Number of samples in the dataset, L: Number of OFDM symbols, K: Number of subcarriers, 2: Real/Imag
samples = np.stack([np.stack(samples).real, np.stack(samples).imag], axis=3)
labels = np.stack([np.stack(labels).real, np.stack(labels).imag], axis=3)
if fileName is not None:
np.save(fileName, np.stack([samples,labels])) # Save the dataset to the specified file
print("\r Done. (%.2f Sec.) Saved to \"%s\". "%(dt, fileName))
else:
print("\r Done. (%.2f Sec.) "%(dt))
return samples, labels
Now we can create the datasets for our deep learning project. The followin cell create 3 dataset files for training, validation, and test. We use 2 frames for time duration and create dataset using a mixture of SNR values 5, 10, 15, 20, and 25 dB. Different seeds are used for different datasets to make sure the data in validation and test datasets are not experienced by the model during the training. Depending on your machine, it can take 10 to 60 minutes to complete.
[4]:
random.setSeed(123)
trainSample, trainlabels = makeDataset(numFrames=2, snrDbs=[5,10,15,20,25],
seeds=random.integers(1000, 2000, 20), fileName="ChestTrain.npy")
validSample, validlabels = makeDataset(numFrames=2, snrDbs=[5,10,15,20,25],
seeds=random.integers(2000, 3000, 3), fileName="ChestValid.npy")
testSample, testlabels = makeDataset(numFrames=2, snrDbs=[5,10,15,20,25],
seeds=random.integers(3000, 4000, 3), fileName="ChestTest.npy")
Making dataset for SNR=[5, 10, 15, 20, 25] dB, with 2 frames and 20 seeds
Done. (572.84 Sec.) Saved to "ChestTrain.npy".
Making dataset for SNR=[5, 10, 15, 20, 25] dB, with 2 frames and 3 seeds
Done. (86.70 Sec.) Saved to "ChestValid.npy".
Making dataset for SNR=[5, 10, 15, 20, 25] dB, with 2 frames and 3 seeds
Done. (86.80 Sec.) Saved to "ChestTest.npy".
[ ]: